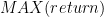Introduction
I am very excited to finally share some of my research exploring Meucci’s (Meucci (2005)) portfolio optimization methods, and how the resulting portfolios compare to the use of historical data. For those unfamiliar with Attilio Meucci, he runs an annual Advanced Risk and Portfolio Management Bootcamp in New York City every summer. The bootcamp attracts academics and professionals within the industry, and over 6 intense days, topics and techniques in Risk Management and Portfolio Management are discussed in depth. I was fortunate to attend the bootcamp during the summer of 2014. In this post, I will be exploring portfolio optimization of the 9 Sector SPDR ETFs, using Meucci’s methods, specifically his framework outlined in “The Checklist” (Meucci (2011)), and I will be verifying if Meucci’s methods add value over the use of historical data. Lastly, I will be using Markowitz’s (Markowitz (1952)) quadratic utility framework for portfolio optimization, and will be comparing results using Minimum Variance and Mean Variance optimizations.
Background
Meucci’s core methods differ from the standard practice insofar as he prefers the use of Profit-and-Loss [P&L] over returns, and he prefers Monte Carlo Simulation over the direct use of historical data. Details of his framework can be found in “The Checklist” (Meucci (2011)), however I will provide a brief summary here:
- For each instrument, one needs to identify the “invariants”, or the drivers of the changes in price that are “Identically and Independently Distributed” [IID]. For equities, this is usually log-returns.
- Once the invariants are identified (e.g. log-returns for equities), this yields a matrix of invariants. To reduce estimation error, dimension reduction is performed by computing the eigenvalues and eigenvectors. Then, a subset of eigenvalues/eigenvectors are identified as the “signal”, whereas the remaining ones are classified as “noise”.
- For the “signal” eigenvalues and eigenvectors, these are converted to their Principal Components [PCs] (i.e. the product of the invariants with the signal-eigenvectors). The distribution for each of the PCs is estimated, as well as the dependence between them (the copula). For the noise components, these are assumed to be distributed with mean 0, and standard deviation equal to the corresponding noise-eigenvalue, and are assumed to be independent/uncorrelated with each other.
- Next, the Monte Carlo Simulation is conducted by drawing N trials, for P periods, from the meta-distribution estimated in the previous step. The idea is that the optimization should occur at some future investment horizon, and thus prices should be projected to where they likely will be.
- Finally, these returns need to be converted to P&Ls, thus the distribution of N invariants at the investment horizon is multiplied by the latest security prices to obtain a distribution of P&Ls.
- Lastly, the portfolio optimization is conducted on the P&Ls, instead of percent returns. Thus, the solution yields holdings (i.e. number of shares for each security) instead of the traditional asset weights.
In order to simplify this process, a number of assumptions were made for this study.
Assumptions
- Only equities are considered, whereas Meucci’s framework includes Fixed Income and Derivatives
- All signal-PCs are assumed to have a skew-student-t distribution
- All noise-PCs are assumed to either be normally distributed, or have student-t distribution, and are selected based on the Anderson-Darling goodness of fit test
- Given that there are 9 sector spdr ETFs, it is assumed that there are always 3 signal PCs, and 6 noise PCs
- The dependence between the 3 signal PCs is assumed to have a Vine Copula (Kramer and Schepsmeier (2011)) structure
- The dependence between the 6 noise PCs is assumed to be uncorrelated within the 6 PCs, as well as uncorrelated with the 3 signal PCs
- Transaction costs are ignored for rebalancing
- The optimization is long-only, fully-invested with a max-weight constraint on the 2 highest volatility ETFs
- For each period, the historical volatility is computed, and for the 2 highest volatility ETFs, their weights are constrained by the inverse-volatility weight calculated for that period
- All other “non-high-volatility” ETFs can be fully-invested (100% of wealth)
- For the Auto-Regressive Moving-Average [ARMA] trials, the ARMA model is fit if the Ljung-Box test indicates autocorrelation with 2.5% statistical significance
- I am aware of criticisms of the Ljung-Box test for autocorrelation
- Weekly data is used to calculate the invariants, eigenvalues/eigenvector and to ultimately solve for holdings
- The rationale is that this eliminates some of the noise from the daily prices, yet provides enough data to draw conclusions
- Performance is evaluated using daily data
- Covariance matrices are estimated using “robust” methodologies
- robust::covRob() was used to estimate covariance matrices
- 3 Windows are selected to evaluate historical horizons
- 18 months is assumed to be a short-horizon window
- 36 months is assumed to be a medium-horizon window
- 60 months is assumed to be a long-horizon window
- Portfolios are rebalanced monthly, thus the Meucci investment horizon is 4-weeks ahead
- The invariants are projected 4 periods ahead, and then re-priced and optimized at this 4-period-ahead horizon
It should also be noted that, I have made many assumptions above. If anyone happened to read my first post on the Low-Volatilty Trading Strategy, then they may wonder why I did not take the hypothesis-driven approach outlined by Peterson (2014). Work on this post started in Q1 2015, months after I had attended Meucci’s bootcamp. Much of the work, assumptions, and results were obtained throughout 2015. I had taken Brian Peterson’s CFRM561 course in the spring/summer of 2016, after much of the work was completed. Due to the number of assumptions, all of which can arguably be converted to testable hypotheses, this would significantly delay the release of this information. I believe I have some valuable conclusions to share based on the work that has already been completed, and thus decided to write this post. Ideally though, all assumptions I have made above would be tested using the methods outlined in Peterson (2014), to ensure that the distributional and dependence assumptions are sound, and to reduce the risk of overfitting.
Result Replication
To replicate the results, two of my packages, titled propfolio and tsconv need to be installed. The following lines of code will install the packages, provided that the devtools library is already installed. Warning: propfolio has a lot of dependencies, so installing it will install many additional packages. Please review the description of the package prior to installing. Code to replicate the results can be found in the appendix.
devtools::install_github("erolbicero/tsconv")
devtools::install_github("erolbicero/propfolio")
ARMA Approach
Throughout 2015, at times during the analysis, I noticed that some of the sectors exhibited autocorrelation (e.g. XLU at times appears to have significant autocorrelation). During the “quest for invariance” step (Meucci (2011)), the result should yield no autocorrelation once the invariant has been identified. Given that I observed autocorrelation, this implied that there was information in the return series that was not being captured. In an effort to obtain uncorrelated residuals (invariants), I decided to verify if there is statistically significant autocorrelation using the Ljung-Box test at 2.5% significance. If the null hypothesis was rejected, then I used forecast::auto.arima() to fit an ARMA model. The only time this additional step is conducted is for the 18 month window. It is an extension of the Monte Carlo approach, and technically more accurate as it ensures that the invariants are IID. I did not do this for the 36 month and 60 month windows, since I did test this previously in 2015, and found that using forecast::auto.arima() did not make performance improvements; if anything it negatively impacted performance.
Optimization Criteria, Objectives and Choice of Benchmark
Objective Function Criteria
The objective in this study is to maximize risk-adjusted returns, or put anther way, obtain the highest level of returns for the lowest amount of risk. Thus, the Sharpe Ratio will predominantly be used to assess strategy performance, however this will be evaluated in the context of the annualized return and annualized volatility. E.g., if the Sharpe Ratio of strategy 1 is 2.0, yet the annualized return is 3%, and if the Sharpe Ratio of strategy 2 is 1.5, yet the annualized return is 9%, then strategy 2 may be preferred over strategy 1.
The objective can be illustrated with the chart below. Once the portfolio or strategy performance is obtained, and the annualized risk and return is calculated, it can be plotted on a risk-return scatter plot to visually compare strategies. The goal is to select the strategy that is the highest to the top-left; this is the lowest risk and highest return strategy. In practice, there are typically no points in this space, and all points usually tend towards the right (i.e. higher risk). If two points are on the same horizontal line (same return), the strategy on left is the best (the “Good” arrow), since it has the same return but lower risk. If two points are on the same vertical line, the strategy on top (the “Better” arrow) is the best, since it has more return for the same level of risk. Any strategy to the top-left of another point is better (the “Great” arrow) since it has higher return and lower risk. Any strategies that fall on some positive-slope line in relation to one another will need to be evaluated on a case-by-case basis, since if they have the same Sharpe Ratio, then they are roughly “equivalent”, however, if the point is significantly higher, and only slightly to the right, then it is equivalent to the effect in the “Better” line, where a significant amount of return is gained for a small increase in risk.
Visualization of Objectives: Maximizing the Sharpe Ratio

Choice of Benchmark
The benchmark for this study will be the equal-weight portfolio of all 9 sector spdrs, rebalanced monthly. It is tempting to select the S&P500 as the benchmark, as it is easier to outperform, however with an equal weight benchmark, not only does it outperform the cap-weighted S&P500 index, it makes no model assumptions and thus is a fair benchmark to be evaluated against.
This outperformance of the equal-weight portfolio over cap-weighted portfolio is clear in the charts and table below, where the equal-weight benchmark exhibits higher annualized returns, lower annualized risk, and better tail characteristics (lower VaR and ETL). The optimizations in this study may outperform the cap-weighted index, however, if they cannot outperform the equal-weight portfolio, then they are not useful, further justifying the use of the equal-weight portfolio as the benchmark.
Cumulative Returns of the S&P 500 (Cap-Weighted) Index vs. Equal-Weighted Sector Portfolio

Risk-Return Scatter of the S&P 500 (Cap-Weighted) Index vs. Equal-Weighted Sector Portfolio

Performance Statistics of the S&P 500 (Cap-Weighted) Index vs. Equal-Weighted Sector Portfolio
(June 2000 – December 2016)
| SPY | Benchmark | |
|---|---|---|
| Annualized Return | 4.65% | 6.94% |
| Annualized Standard Deviation | 19.62% | 18.58% |
| Semi-Deviation | 14.04% | 13.44% |
| Annualized Sharpe Ratio (Rf=0%) | 0.24 | 0.37 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.32 | 0.42 |
| Average Drawdown | 2.3% | 2.21% |
| Average Recovery | 20.62 | 13.17 |
| VaR 95 | -1.94% | -1.79% |
| VaR 99 | -3.46% | -3.26% |
| ETL 95 | -2.93% | -2.81% |
| ETL 99 | -4.85% | -4.66% |
| Worst Loss | -9.84% | -9.58% |
| Skewness | 0.19 | -0.09 |
| Excess Kurtosis | 11.62 | 8.59 |
| Information Ratio | -0.49 | NaN |
Overall Structure and Process
First, the Minimum Variance Optimization will be evaluated for each time window, where Meucci’s Monte Carlo approach will be compared to the historical method. The stronger strategy, i.e. Historical vs. Monte Carlo, will be identified for each window length.
Next, the same comparison (Historical vs. Monte Carlo) will be evaluated for the Optimal Sharpe criterion, within each window length.
Lastly, a summary of outperforming strategies relative to the benchmark will be identified, and then it can be assessed whether or not the Monte Carlo [MC] approach adds value over the benchmark and the historical method.
Historical vs. Monte Carlo Performance for Minimum Variance Optimization
Performance Comparison
60 Month Window
In this case, performance of the MC approach vs. the historical approach are virtually indistinguishable from one another. Both strategies exhibit comparable risk and return characteristics. Drawdowns are lower for both MC and historical approaches vs. the benchmark. On the risk-return scatter, we can see that both strategies are in the “Good” scenario, where they appear to exhibit lower risk vs. the benchmark. This is confirmed in the t-test and F-tests below, where the MC and historical methods are statistically indistinguishable, whereas the historical method has statistically significantly lower risk vs. the benchmark.
I do not interpret this to conclude that the MC approach adds no value here. One possible interpretation is that the MC approach confirms that a “global minimum variance” portfolio has been identified, insofar as both strategies select the same sector ETFs with comparable weights across time. However, there is not enough information here to conclude whether or not this is true, or if the MC approach adds no value over the historical method.
Given the choice between the two methods, since the historical approach is more simple, I would likely use this approach, given that it is indistinguishable from the MC approach.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(60 Month Window)
(December 2003 – December 2016)
| Minimum.Variance.60mo.Hist | Minimum.Variance.60mo.MC | Benchmark | |
|---|---|---|---|
| Annualized Return | 9.18% | 9.15% | 8.93% |
| Annualized Standard Deviation | 13.23% | 13.2% | 18.34% |
| Semi-Deviation | 9.6% | 9.6% | 13.37% |
| Annualized Sharpe Ratio (Rf=0%) | 0.69 | 0.69 | 0.49 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.57 | 0.57 | 0.47 |
| Average Drawdown | 1.47% | 1.44% | 1.91% |
| Average Recovery | 9.5 | 9.38 | 9.47 |
| VaR 95 | -1.23% | -1.25% | -1.71% |
| VaR 99 | -2.39% | -2.4% | -3.55% |
| ETL 95 | -1.95% | -1.96% | -2.84% |
| ETL 99 | -3.32% | -3.3% | -4.91% |
| Worst Loss | -6.43% | -6.61% | -9.58% |
| Skewness | -0.11 | -0.12 | -0.16 |
| Excess Kurtosis | 9.01 | 9.19 | 10.92 |
| Information Ratio | 0.03 | 0.02 | NaN |
## [1] "Paired t-test (mean difference) for 'Minimum Variance 60mo Hist' vs. 'Minimum Variance 60mo MC'"## [1] "p-value = 0.94"## [1] "F-test (ratio of variances) for 'Minimum Variance 60mo Hist' vs. 'Minimum Variance 60mo MC'"## [1] "p-value = 0.92"## [1] "Paired t-test (mean difference) for 'Minimum Variance 60mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.82"## [1] "F-test (ratio of variances) for 'Minimum Variance 60mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"36 Month Window
Here, we have a very similar result to the 60 month window, except it appears as though the mean return is worse than the benchmark, especially when we look at the risk-return scatter plot below. However, given that the Sharpe Ratio for both the MC and historical approach are comparable to the Sharpe Ratio of the benchmark, and, given that the risk for both strategies is statistically significantly lower (confirmed in the F-test below), if the strategies were to be levered up to the volatility of the benchmark, then comparable returns would be generated. Furthermore, the mean difference for the return distributions of the strategies is not statistically significantly different from that of the benchmark (confirmed with the t-test below), therefore, my interpretation is that this is a similar case to the 60 month window, where the performance of MC and historical vs. the benchmark are comparable, and a statistically significant reduction of risk in the portfolios is obtained.
Again, given the simplicity of the historical approach, I would select the historical method over the MC approach.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(36 Month Window)
(December 2001 – December 2016)
| Minimum.Variance.36mo.Hist | Minimum.Variance.36mo.MC | Benchmark | |
|---|---|---|---|
| Annualized Return | 6.7% | 6.48% | 7.94% |
| Annualized Standard Deviation | 13.97% | 14.07% | 18.65% |
| Semi-Deviation | 10.1% | 10.2% | 13.49% |
| Annualized Sharpe Ratio (Rf=0%) | 0.48 | 0.46 | 0.43 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.48 | 0.46 | 0.45 |
| Average Drawdown | 1.84% | 1.86% | 2.11% |
| Average Recovery | 15 | 15.64 | 11.18 |
| VaR 95 | -1.38% | -1.34% | -1.8% |
| VaR 99 | -2.53% | -2.5% | -3.31% |
| ETL 95 | -2.07% | -2.09% | -2.84% |
| ETL 99 | -3.34% | -3.43% | -4.75% |
| Worst Loss | -6.69% | -7.43% | -9.58% |
| Skewness | -0.04 | -0.08 | -0.08 |
| Excess Kurtosis | 7.83 | 9.37 | 9.16 |
| Information Ratio | -0.14 | -0.16 | NaN |
## [1] "Paired t-test (mean difference) for 'Minimum Variance 36mo Hist' vs. 'Minimum Variance 36mo MC'"## [1] "p-value = 0.68"## [1] "F-test (ratio of variances) for 'Minimum Variance 36mo Hist' vs. 'Minimum Variance 36mo MC'"## [1] "p-value = 0.67"## [1] "Paired t-test (mean difference) for 'Minimum Variance 36mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.41"## [1] "F-test (ratio of variances) for 'Minimum Variance 36mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"18 Month Window
In this instance, it appears as though the results are indistinguishable from the benchmark, both for the historical and MC approaches. However, upon further inspection of the risk characteristics, what we have is the same return for both the historical and MC approaches for statistically significantly less risk vs. the benchmark (confirmed in the F-test below). Upon inspection of the risk-return scatter plot, the “Good” scenario can be observed, where all 3 strategies (historical, MC and ARMA) exhibit statistically significantly lower risk vs. the benchmark.
Again, since the historical approach is comparable to both the MC and ARMA approaches, given a choice I would select the historical approach due to its simplicity.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(18 Month Window)
(June 2000 – December 2016)
| Minimum.Variance.18mo.Hist | Minimum.Variance.18mo.MC | Minimum.Variance.18mo.ARMA | Benchmark | |
|---|---|---|---|---|
| Annualized Return | 7.11% | 6.86% | 7.25% | 6.94% |
| Annualized Standard Deviation | 13.94% | 13.87% | 13.99% | 18.58% |
| Semi-Deviation | 10.1% | 10.04% | 10.09% | 13.44% |
| Annualized Sharpe Ratio (Rf=0%) | 0.51 | 0.49 | 0.52 | 0.37 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.51 | 0.5 | 0.52 | 0.42 |
| Average Drawdown | 1.82% | 1.92% | 1.8% | 2.21% |
| Average Recovery | 13.99 | 15.87 | 13.46 | 13.17 |
| VaR 95 | -1.37% | -1.38% | -1.35% | -1.79% |
| VaR 99 | -2.53% | -2.48% | -2.5% | -3.26% |
| ETL 95 | -2.05% | -2.04% | -2.05% | -2.81% |
| ETL 99 | -3.3% | -3.28% | -3.33% | -4.66% |
| Worst Loss | -6.69% | -6.42% | -6.59% | -9.58% |
| Skewness | -0.13 | -0.12 | -0.1 | -0.09 |
| Excess Kurtosis | 5.84 | 5.87 | 5.92 | 8.59 |
| Information Ratio | 0.02 | -0.01 | 0.03 | NaN |
## [1] "Paired t-test (mean difference) for 'Minimum Variance 18mo Hist' vs. 'Minimum Variance 18mo ARMA'"## [1] "p-value = 0.85"## [1] "F-test (ratio of variances) for 'Minimum Variance 18mo Hist' vs. 'Minimum Variance 18mo ARMA'"## [1] "p-value = 0.8"## [1] "Paired t-test (mean difference) for 'Minimum Variance 18mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.79"## [1] "F-test (ratio of variances) for 'Minimum Variance 18mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"## [1] "Paired t-test (mean difference) for 'Minimum Variance 18mo ARMA' vs. 'Benchmark'"## [1] "p-value = 0.86"## [1] "F-test (ratio of variances) for 'Minimum Variance 18mo ARMA' vs. 'Benchmark'"## [1] "p-value = 0"Section Results
In all the window lengths, both the historical method and MC approach exhibited statistically significantly lower risk vs. the benchmark, however between the two strategies, they were virtually indistinguishable.
My interpretation is that, since minimum variance optimization effectively ignores any return inputs, either the MC (and ARMA) approaches are confirming that the historical method is finding the global minimum variance portfolio, or it adds no value. What is needed is return information to verify if adding return information as an input into the optimization enables a distinction in the performance between MC and historical approaches. This will be investigated in the subsequent section.
Historical vs. Monte Carlo Performance for Optimal Sharpe Ratio Optimization
Performance Comparison
60 Month Window
In this particular case, the MC approach is a poor performing strategy, when compared to both the benchmark and the historical method. The historical method manages to maintain the same level of return, with a statistically significantly lower risk, however the MC approach performs very poorly, especially since the t-test comparing the return distribution between both approaches is fairly low at 0.13, indicating that there is a chance that the returns are statistically significantly different.
It appears as though the MC approach at this window length is unable to capture the correct return characteristics, which yields the extremely poor performance vs. both the benchmark and historical method.
Thus, the historical approach is still preferred at the 60 month window length.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(60 Month Window)
(December 2003 – December 2016)
| Optimal.Sharpe.60mo.Hist | Optimal.Sharpe.60mo.MC | Benchmark | |
|---|---|---|---|
| Annualized Return | 8.92% | 5.75% | 8.93% |
| Annualized Standard Deviation | 16.09% | 16.45% | 18.34% |
| Semi-Deviation | 11.65% | 11.77% | 13.37% |
| Annualized Sharpe Ratio (Rf=0%) | 0.55 | 0.35 | 0.49 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.51 | 0.38 | 0.47 |
| Average Drawdown | 1.91% | 2.08% | 1.91% |
| Average Recovery | 13.4 | 19.55 | 9.47 |
| VaR 95 | -1.55% | -1.5% | -1.71% |
| VaR 99 | -2.95% | -2.85% | -3.55% |
| ETL 95 | -2.41% | -2.42% | -2.84% |
| ETL 99 | -3.96% | -4.24% | -4.91% |
| Worst Loss | -7.79% | -9.45% | -9.58% |
| Skewness | 0.14 | 0.39 | -0.16 |
| Excess Kurtosis | 11.78 | 17.46 | 10.92 |
| Information Ratio | 0 | -0.31 | NaN |
## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 60mo Hist' vs. 'Optimal Sharpe 60mo MC'"## [1] "p-value = 0.13"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 60mo Hist' vs. 'Optimal Sharpe 60mo MC'"## [1] "p-value = 0.2"## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 60mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.87"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 60mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"36 Month Window
In this scenario, it almost appears as though similar results are obtained as the minimum variance optimization case, insofar as the returns are lower (yet not statistically significantly different), and the risk is statistically significantly lower, both for the MC and historical approaches vs. the benchmark. However, in the minimum variance case, the Sharpe Ratio for both strategies was comparable to the Sharpe Ratio of the benchmark, yet in this case, it is much lower (0.45 vs. 0.38 and 0.37, benchmark vs. historical and MC, respectively). Thus, theoretically levering the strategies to the volatility of the benchmark would yield portfolios that exhibit comparable returns with higher risk.
Thus, both the MC and historical approaches are poor performers vs. the benchmark in this scenario, and the benchmark should be used over any approach.
What is interesting in this case, is that the MC approach exhibits statistically significantly lower risk vs. the historical approach. This implies that the MC approach is capturing the risk and return characteristics better than the historical approach at this window length, which is a positive characteristic of the MC approach, and can be used in future studies to potentially improve the performance over the benchmark.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(36 Month Window)
(December 2001 – December 2016)
| Optimal.Sharpe.36mo.Hist | Optimal.Sharpe.36mo.MC | Benchmark | |
|---|---|---|---|
| Annualized Return | 5.33% | 5.13% | 7.94% |
| Annualized Standard Deviation | 16.35% | 15.81% | 18.65% |
| Semi-Deviation | 11.79% | 11.24% | 13.49% |
| Annualized Sharpe Ratio (Rf=0%) | 0.33 | 0.32 | 0.43 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.38 | 0.37 | 0.45 |
| Average Drawdown | 2.41% | 2.21% | 2.11% |
| Average Recovery | 17.17 | 18.28 | 11.18 |
| VaR 95 | -1.62% | -1.48% | -1.8% |
| VaR 99 | -2.97% | -2.7% | -3.31% |
| ETL 95 | -2.43% | -2.3% | -2.84% |
| ETL 99 | -3.87% | -3.76% | -4.75% |
| Worst Loss | -7.14% | -6.94% | -9.58% |
| Skewness | 0.08 | 0.42 | -0.08 |
| Excess Kurtosis | 7.73 | 13.06 | 9.16 |
| Information Ratio | -0.29 | -0.29 | NaN |
## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 36mo Hist' vs. 'Optimal Sharpe 36mo MC'"## [1] "p-value = 0.89"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 36mo Hist' vs. 'Optimal Sharpe 36mo MC'"## [1] "p-value = 0.04"## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 36mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.21"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 36mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"18 Month Window
Here, the MC approach begins to exhibit strong performance over the historical approach, especially when the ARMA method is used. This is clear from the cumulative return chart, where ARMA and MC are the long-run strong performers, as well as the drawdown chart, where the benchmark appears to have the worst drawdowns, and the historical approach appears to have a sluggish post-financial-crisis recovery vs. the MC and ARMA strategies. Upon examining the risk-return scatter, the “Great” scenario can be observed, where the ARMA strategy is to the top-left of the benchmark.
Here, the historical, MC and ARMA approaches all have statistically significantly lower risk vs. the benchmark, however, all of the return distributions are statistically indistinguishable. What is interesting about the ARMA strategy, is that the average drawdown-recovery is lower than that of the historical approach. Lastly, both VaR 100 (i.e. worst loss) are lowest for the MC and ARMA approaches.
My own concern with the ARMA approach, is that I did not test the quality of the signal process, nor did I conduct any tests for overfitting, thus I am cautious with these results. However, it is the more correct approach for Meucci’s methods insofar as it ensures that the invariants are IID.
Therefore, it appears that at lower window lengths, the power of Meucci’s MC approach is quantifiable, even if only the MC approach is used (i.e. not the ARMA approach), insofar as it yields lower risk with a higher Sharpe Ratio vs. both the benchmark and historical method. This is supported when evaluating the 36 month window, where the MC approach exhibited better risk characteristics vs. the historical approach.
Historical vs. Monte Carlo Cumulative Returns

Historical vs. Monte Carlo Drawdown

Historical vs. Monte Carlo Risk-Return Scatter

Performance Statistics of Historical vs. Monte Carlo Approaches
(18 Month Window)
(June 2000 – December 2016)
| Optimal.Sharpe.18mo.Hist | Optimal.Sharpe.18mo.MC | Optimal.Sharpe.18mo.ARMA | Benchmark | |
|---|---|---|---|---|
| Annualized Return | 7.34% | 7.4% | 8.81% | 6.94% |
| Annualized Standard Deviation | 16.18% | 15.13% | 15.56% | 18.58% |
| Semi-Deviation | 11.76% | 11.07% | 11.34% | 13.44% |
| Annualized Sharpe Ratio (Rf=0%) | 0.45 | 0.49 | 0.57 | 0.37 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.46 | 0.51 | 0.54 | 0.42 |
| Average Drawdown | 2.22% | 2.11% | 2.05% | 2.21% |
| Average Recovery | 17.59 | 15.26 | 13.24 | 13.17 |
| VaR 95 | -1.57% | -1.57% | -1.54% | -1.79% |
| VaR 99 | -2.88% | -2.72% | -2.83% | -3.26% |
| ETL 95 | -2.4% | -2.26% | -2.31% | -2.81% |
| ETL 99 | -3.98% | -3.47% | -3.76% | -4.66% |
| Worst Loss | -9.37% | -6.04% | -8.53% | -9.58% |
| Skewness | -0.08 | -0.25 | -0.28 | -0.09 |
| Excess Kurtosis | 9.67 | 3.64 | 5.97 | 8.59 |
| Information Ratio | 0.04 | 0.04 | 0.16 | NaN |
## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 18mo Hist' vs. 'Optimal Sharpe 18mo ARMA'"## [1] "p-value = 0.59"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 18mo Hist' vs. 'Optimal Sharpe 18mo ARMA'"## [1] "p-value = 0.01"## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 18mo Hist' vs. 'Optimal Sharpe 18mo MC'"## [1] "p-value = 0.96"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 18mo Hist' vs. 'Optimal Sharpe 18mo MC'"## [1] "p-value = 0"## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 18mo Hist' vs. 'Benchmark'"## [1] "p-value = 0.98"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 18mo Hist' vs. 'Benchmark'"## [1] "p-value = 0"## [1] "Paired t-test (mean difference) for 'Optimal Sharpe 18mo ARMA' vs. 'Benchmark'"## [1] "p-value = 0.67"## [1] "F-test (ratio of variances) for 'Optimal Sharpe 18mo ARMA' vs. 'Benchmark'"## [1] "p-value = 0"Section Results
It appears as though, at shorter window lengths, the power of the MC approach begins to surface insofar as the the risk of the strategies is statistically significantly lower. In order to assess if the MC approach is truly optimal, a comparison of the strongest strategies across window periods and optimization methods is required to assess if it is truly a superior strategy. This will be the goal in the next section.
Overall Comparison and Identifying the Optimal Strategy
Upon comparing the results above, the clear performers are:
- Historical Minimum Variance (60 Months)
- Monte Carlo Optimal Sharpe (18 Months)
- ARMA Optimal Sharpe (18 Months)
Which is summarized in the table below.
| 18 Months | 36 Months | 60 Months | |
|---|---|---|---|
| Minimum Variance | H | H | H |
| Optimal Sharpe | A | M | H |
| Overall Performer | OS | MV | MV |
Where:
- H: Historical
- M: Monte Carlo
- A: ARMA
- OS: Optimal Sharpe
- MV: Minimum Variance
The 36 month window is excluded since it could not outperform the benchmark in all tests.
18 Month vs. 60 Month Windows
In order to identify the true top performer, the results for 18 month window are re-run with the same window length as the 60 month window. Upon inspecting the cumulative returns, it is clear that both the 18 month MC and ARMA approaches exhibit strong returns. The t-test below confirms that the 18 month ARMA Optimal Sharpe has relatively statistically significantly different returns vs. the 60 month Historical Minimum Variance strategy. Both 18 month strategies (ARMA and MC) exhibit statistically significantly lower risk vs. the 60 month Minimum Variance strategy. Thus, based on these results, and the constraints within this study, Meucci’s methods appear to add significant value over historical data, if they are used with relatively shorter time windows (i.e. < 60 months).
Top Performing Strategy Cumulative Returns

Top Performing Strategy Drawdown

Top Performing Strategy Risk-Return Scatter

Performance Statistics of Top Performing Strategies
(18 Month vs. 60 Month Windows)
(December 2003 – December 2016)
| Minimum.Variance.60mo.Hist | Optimal.Sharpe.18mo.MC | Optimal.Sharpe.18mo.ARMA | Benchmark | |
|---|---|---|---|---|
| Annualized Return | 9.18% | 10.52% | 12.13% | 8.93% |
| Annualized Standard Deviation | 13.23% | 14.46% | 14.53% | 18.34% |
| Semi-Deviation | 9.6% | 10.74% | 10.76% | 13.37% |
| Annualized Sharpe Ratio (Rf=0%) | 0.69 | 0.73 | 0.83 | 0.49 |
| Adjusted Sharpe ratio (Risk free = 0) | 0.57 | 0.64 | 0.67 | 0.47 |
| Average Drawdown | 1.47% | 1.82% | 1.73% | 1.91% |
| Average Recovery | 9.5 | 10.64 | 9.2 | 9.47 |
| VaR 95 | -1.23% | -1.51% | -1.48% | -1.71% |
| VaR 99 | -2.39% | -2.7% | -2.7% | -3.55% |
| ETL 95 | -1.95% | -2.22% | -2.21% | -2.84% |
| ETL 99 | -3.32% | -3.5% | -3.6% | -4.91% |
| Worst Loss | -6.43% | -6.04% | -6.84% | -9.58% |
| Skewness | -0.11 | -0.42 | -0.4 | -0.16 |
| Excess Kurtosis | 9.01 | 4.45 | 5.29 | 10.92 |
| Information Ratio | 0.03 | 0.16 | 0.31 | NaN |
## [1] "Paired t-test (mean difference) for 'Minimum Variance 60mo Hist' vs. 'Optimal Sharpe 18mo ARMA'"## [1] "p-value = 0.12"## [1] "F-test (ratio of variances) for 'Minimum Variance 60mo Hist' vs. 'Optimal Sharpe 18mo ARMA'"## [1] "p-value = 0"## [1] "Paired t-test (mean difference) for 'Minimum Variance 60mo Hist' vs. 'Optimal Sharpe 18mo MC'"## [1] "p-value = 0.46"## [1] "F-test (ratio of variances) for 'Minimum Variance 60mo Hist' vs. 'Optimal Sharpe 18mo MC'"## [1] "p-value = 0"Final Thoughts and Overall Conclusion
There is one additional consideration that needs attention. I assumed no transaction costs, and given the shorter time horizon of the 18 month strategies, as well as the optimization method (Optimal Sharpe vs. Minimum Variance), when the weights are plotted for each of the strategies, it is clear that the 18 month ARMA and MC strategies are not really portfolio management strategies; they exhibit characteristics of tactical trading strategies due to the aggressively changing portfolio weights.
Thus, if the objective is for stable portfolio weights, then a long horizon window and minimum variance optimization appears to be a better choice under this particular study, due to the relatively stable weights. However, if there is appetite for complexity, and individual transaction costs are low, then there is potential to add more value using Attilio Meucci’s methods.
It may be possible to stabilize the weights under the 18 month scenarios, however it is out of scope for this study, and may be something valuable to investigate at a later date.
Rolling Weights for Minimum Variance Optimal Strategy

Rolling Weights for Optimal Sharpe Optimal Strategy

Rolling Weights for Optimal Sharpe Optimal Strategy

Opportunities for Future Research
Based on the work in this study, I think there is a lot of opportunity to explore the power of Meucci’s methods. I do think there is a lot of potential for horizons
- Start hypothesis testing from first-principles to reduce the number of assumptions (e.g. signal-PC distribution)
- Add additional well-thought-out bias to assist with out-of-sample performance
- Use Cross Validation to evaluate distribution and copula fitting
- Verify predictive ability of the ARMA process
- Add concentration constraints to Optimal Sharpe optimization to stabilize asset weights, especially in the 18-month window
- Identify different regimes (e.g. High vs. Low volatility) and apply different models/hypotheses/assumptions to each regime
Please contact me if you have any questions/comments/feedback or you have any ideas. I hope you found this interesting and useful.
© 2016 Erol Biceroglu

Appendix: Code to Replicate Results
Historical strategy code:
library(propfolio)
library(robust)
library(PerformanceAnalytics)
library(foreach)
library(doParallel)
nYears <- c(5,3,1.5) #set this to the 1st index for 60 months, 2nd index for 36 months or 3rd for 18 months
nYears <- nYears[1]
freq <- "weekly"
freqScale <- switch(freq, daily = 252, weekly = 52, monthly = 12, quarterly = 4, yearly = 1, stop("undefined"))
#########
#Start from scratch
symb <- c("XLE"
,"XLU"
,"XLK"
,"XLB"
,"XLP"
,"XLY"
,"XLI"
,"XLV"
,"XLF"
)
optTestPriceXtsMatrixALLweekly <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
optTestPriceXtsMatrixALLdaily <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
SPY <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
SPYd <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
RSP <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
RSPd <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
cl <- makeForkCluster(detectCores())
registerDoParallel(cl)
loopStart <- Sys.time()
rollingOptimizationResults<-
foreach(dateIndex = toRowList(createRollingTimeIndices(index(optTestPriceXtsMatrixALLweekly), estimationLength = 52*nYears, timeUnit = "weeks", investmentHorizonLength = 4))
, .errorhandling = "pass"
) %dopar%
{
#allocate date indices
OOSIndex <- as.vector(dateIndex[2])
pseudoISPeriodPlot <- as.vector(dateIndex[3])
dateIndex <- as.vector(dateIndex[1])
#filter out time series object
optTestPriceXtsMatrix <- optTestPriceXtsMatrixALLweekly[dateIndex]
#extract "horizon" prices
optTestLatestPrices <- as.vector(last(optTestPriceXtsMatrix))
#compute linear returns
optTestLRetXtsMatrix <- retMatrixL(optTestPriceXtsMatrix)
#convert historical prices to change in prices (using horizon prices)
optTestLRetXtsMatrixPnL <- coredata(do.call(merge,lapply(1:length(optTestLatestPrices)
,function(x){optTestLRetXtsMatrix[,x] * optTestLatestPrices[x]}
)))
#compute moments
covRobResults <- robust::covRob(data = optTestLRetXtsMatrixPnL)
optTestRobMean <- as.vector(covRobResults$center)
optTestRobCovPnL <- covRobResults$cov
#compute historical inverse volatility weights (for constraints)
sdWeightVec <- 1/apply(optTestLRetXtsMatrix,2,sd)/sum(1/apply(optTestLRetXtsMatrix,2,sd))
#extract 7 lowest volatility names (highest 2 will be constrained by inverse volatility weight)
constraintNames <- names(which(rank(sdWeightVec)>=7))
sdWeightVecConstraint <- sdWeightVec[constraintNames]
#compute efficient frontier
LongOnly <- TRUE
optTestOptimizedPortfolio <-
optimizeMeanVariancePortfolio( meanVector = optTestRobMean
, covarianceMatrix = optTestRobCovPnL
, horizonPriceVector = optTestLatestPrices
, horizonPnLMatrix = optTestLRetXtsMatrixPnL
, wealthBalance = 10000
, maxWeightConstraint = list( names = constraintNames #safe weights
, constraintWeight = sdWeightVec #all weights
, maxWeight = ifelse(LongOnly,1,100)
)
, colNames = names(optTestPriceXtsMatrix)
, longOnly = LongOnly
)
return(
list(
estimationPeriod = dateIndex
, OOSPeriod = OOSIndex
, pseudoISPeriodPlot = pseudoISPeriodPlot
, optimalResult = optTestOptimizedPortfolio$optimalResult
, minVarResult = optTestOptimizedPortfolio$minVarResult
, expectedReturn = optTestOptimizedPortfolio$expectedReturn
, standardDeviation = optTestOptimizedPortfolio$standardDeviation
)
)
}
stopCluster(cl=cl)
closeAllConnections()
gc()
cl <- NULL
loopEnd <- Sys.time()
loopEnd - loopStart
# Time difference of 52.48464 mins on 8 cores
#create final result list object
rollingOptimizationResults <- list( portfolioNames = names(optTestPriceXtsMatrixALLweekly)
, portfolioFreq = "weeks"
, portfolioStats = rollingOptimizationResults
)
Monte Carlo Simulation strategy code
library(propfolio)
library(robust)
library(PerformanceAnalytics)
library(foreach)
library(doParallel)
nYears <- c(5,3,1.5) #set this to the 1st index for 60 months, 2nd index for 36 months or 3rd for 18 months
nYears <- nYears[1]
freq <- "weekly"
freqScale <- switch(freq, daily = 252, weekly = 52, monthly = 12, quarterly = 4, yearly = 1, stop("undefined"))
#########
#Start from scratch
symb <- c("XLE"
,"XLU"
,"XLK"
,"XLB"
,"XLP"
,"XLY"
,"XLI"
,"XLV"
,"XLF"
)
optTestPriceXtsMatrixALLweekly <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
optTestPriceXtsMatrixALLdaily <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
SPY <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
SPYd <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
RSP <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
RSPd <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
cl <- makeForkCluster(detectCores())
loopStart <- Sys.time()
rollingOptimizationResults<-
parLapply( cl = cl
, toRowList(createRollingTimeIndices(index(optTestPriceXtsMatrixALLweekly), estimationLength = 52*nYears, timeUnit = "weeks", investmentHorizonLength = 4))
,function(dateIndex)
{
#allocate date indices
OOSIndex <- as.vector(dateIndex[2])
pseudoISPeriodPlot <- as.vector(dateIndex[3])
dateIndex <- as.vector(dateIndex[1])
#filter out time series object
optTestPriceXtsMatrix <- optTestPriceXtsMatrixALLweekly[dateIndex]
#calculate log returns
optTestCRetXtsMatrix <- retMatrixC(optTestPriceXtsMatrix)
#eigen/dimension reduction
optTestRobCov <- robust::covRob(coredata(optTestCRetXtsMatrix))$cov
optTesteig <- eigenDimensionReduction(optTestRobCov)
#Identify dominant eigenvectors
optTestSigNoise <- dominantEigenvectors(optTesteig)
#fitting signal and noise marginals
optTestSigMarginalFits <- fitMarginalSignal(optTestCRetXtsMatrix, optTestSigNoise$signal$eigenValues, optTestSigNoise$signal$eigenVectors)
optTestNoiseMarginalFits <- fitMarginalResidual(optTestCRetXtsMatrix, optTestSigNoise$noise$eigenValues, optTestSigNoise$noise$eigenVectors)
#fit copula
optTestCopulaFit <- fitCopula( coredata(tsEigenProduct(optTestCRetXtsMatrix, optTestSigNoise$signal$eigenVectors)))
#simulate data to horizon
optTestSimulatedInvariantsToHorizon <- simulateDataToHorizon( numSimulations = 52*200
, numPeriodsForward = 4 #22
, vineCopulaFit = optTestCopulaFit
, signalMarginalFit = optTestSigMarginalFits$fits
, residualMarginalFit = optTestNoiseMarginalFits$fits
, eigenVectors = optTesteig$eigenVectors #all eigenvectors
)
#dim(optTestSimulatedInvariantsToHorizon)
#pricing
optTestHorizonPriceVector <- as.vector(coredata(optTestPriceXtsMatrix[nrow(optTestPriceXtsMatrix),]))
optTestHorizonPrices <- horizonPrices( simulatedHorizonInvariants = optTestSimulatedInvariantsToHorizon
, horizonPriceVector = optTestHorizonPriceVector
)
#extract horizon profit-and-loss
optTestHorizonPnLs <- horizonPnLs( simulatedHorizonPrices = optTestHorizonPrices
, horizonPriceVector = optTestHorizonPriceVector
)
#compute moments
covRobResults <- robust::covRob(data = optTestHorizonPnLs)
optTestHorizonRobMean <- as.vector(covRobResults$center)
optTestHorizonRobCovPnL <- covRobResults$cov
#compute historical inverse volatility weights (for constraints)
sdWeightVec <- 1/apply(optTestCRetXtsMatrix,2,sd)/sum(1/apply(optTestCRetXtsMatrix,2,sd))
#extract 7 lowest volatility names (highest 2 will be constrained by inverse volatility weight)
constraintNames <- names(which(rank(sdWeightVec)>=7))
sdWeightVecConstraint <- sdWeightVec[constraintNames]
#compute efficient frontier
LongOnly <- TRUE
optTestOptimizedPortfolio <-
optimizeMeanVariancePortfolio( meanVector = optTestHorizonRobMean
, covarianceMatrix = optTestHorizonRobCovPnL
, horizonPriceVector = optTestHorizonPriceVector
, horizonPnLMatrix = optTestHorizonPnLs
, wealthBalance = 10000
, maxWeightConstraint = list( names = constraintNames #safe weights
, constraintWeight = sdWeightVec #all weights
, maxWeight = ifelse(LongOnly,1,100)
)
, colNames = names(optTestPriceXtsMatrix)
, longOnly = LongOnly
)
return(
list(
estimationPeriod = dateIndex
, OOSPeriod = OOSIndex
, pseudoISPeriodPlot = pseudoISPeriodPlot
, optimalResult = optTestOptimizedPortfolio$optimalResult
, minVarResult = optTestOptimizedPortfolio$minVarResult
, expectedReturn = optTestOptimizedPortfolio$expectedReturn
, standardDeviation = optTestOptimizedPortfolio$standardDeviation
, fitData = list(signalMarginals = optTestSigMarginalFits$evaluation
, noiseMarginals = optTestNoiseMarginalFits$evaluation
, copula = -999
)
)
)
})
stopCluster(cl=cl)
closeAllConnections()
gc()
cl <- NULL
loopEnd <- Sys.time()
loopEnd - loopStart
# Time difference of 11.50882 mins #aws 64 cores
#create final result list object
rollingOptimizationResults <- list( portfolioNames = names(optTestPriceXtsMatrixALLweekly)
, portfolioFreq = "weeks"
, portfolioStats = rollingOptimizationResults
)
Monte Carlo with ARMA strategy code:
library(propfolio)
library(robust)
library(PerformanceAnalytics)
library(foreach)
library(doParallel)
nYears <- c(5,3,1.5) #set this to the 1st index for 60 months, 2nd index for 36 months or 3rd for 18 months
nYears <- nYears[1]
freq <- "weekly"
freqScale <- switch(freq, daily = 252, weekly = 52, monthly = 12, quarterly = 4, yearly = 1, stop("undefined"))
#########
#Start from scratch
symb <- c("XLE"
,"XLU"
,"XLK"
,"XLB"
,"XLP"
,"XLY"
,"XLI"
,"XLV"
,"XLF"
)
optTestPriceXtsMatrixALLweekly <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
optTestPriceXtsMatrixALLdaily <- importEquityPricesToXtsMatrix(symbolVector = symb
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
SPY <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
SPYd <- importEquityPricesToXtsMatrix(symbolVector = "SPY"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
RSP <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = freq
, keep = FALSE
)
RSPd <- importEquityPricesToXtsMatrix(symbolVector = "RSP"
, startDate = "1998-01-01"
, endDate = "2016-12-30"
, priceType = "Adjusted"
, freq = "daily"
, keep = FALSE
)
cl <- makeForkCluster(detectCores())
registerDoParallel(cl)
loopStart <- Sys.time()
rollingOptimizationResults<-
foreach(dateIndex = toRowList(createRollingTimeIndices(index(optTestPriceXtsMatrixALLweekly), estimationLength = 52*nYears, timeUnit = "weeks", investmentHorizonLength = 4))
, .errorhandling = "pass"
) %dopar%
{
#allocate date indices
OOSIndex <- as.vector(dateIndex[2])
pseudoISPeriodPlot <- as.vector(dateIndex[3])
dateIndex <- as.vector(dateIndex[1])
#filter out time series object
optTestPriceXtsMatrix <- optTestPriceXtsMatrixALLweekly[dateIndex]
#calculate log returns
optTestCRetXtsMatrix <- retMatrixC(optTestPriceXtsMatrix)
#verify autocorrelation
corrTheshold <- 0.025
#stats::Box.test(x = , type = "Ljung-Box")
#check if correlation is above threshold, for lag = 1
corrVector<-
sapply(optTestCRetXtsMatrix
, function(x){
LBtest <- stats::Box.test(x = x, type = "Ljung-Box")
LBpvalue <- LBtest$p.value
return(LBpvalue)
}
)
corrIDX <- which(corrVector <= corrTheshold)
#if autocorrelation, fit ARMA model
arimaModels <-
lapply(corrIDX
, function(x){
vectorToFit <- optTestCRetXtsMatrix[,x]
arimaFit <- forecast::auto.arima(x = vectorToFit)
return(arimaFit)
}
)
residualData <- do.call(cbind,lapply(arimaModels
, function(x){
x$residuals
}
))
combinedInvariants <- NULL
for(idx in 1:ncol(optTestCRetXtsMatrix)){
if(idx %in% corrIDX){
combinedInvariants <- cbind(combinedInvariants
, if(length(corrIDX)==1){residualData} else {residualData[,which(idx == corrIDX)]}
)
} else {
combinedInvariants <- cbind(combinedInvariants, coredata(optTestCRetXtsMatrix[,idx]))
}
}
colnames(combinedInvariants) <- symb
#eigen/dimension reduction
optTestRobCov <- robust::covRob(coredata(combinedInvariants))$cov
optTesteig <- eigenDimensionReduction(optTestRobCov)
#Identify dominant eigenvectors
optTestSigNoise <- dominantEigenvectors(optTesteig)
#fitting signal and noise marginals
optTestSigMarginalFits <- fitMarginalSignal(optTestCRetXtsMatrix, optTestSigNoise$signal$eigenValues, optTestSigNoise$signal$eigenVectors)
optTestNoiseMarginalFits <- fitMarginalResidual(optTestCRetXtsMatrix, optTestSigNoise$noise$eigenValues, optTestSigNoise$noise$eigenVectors)
#fit copula
optTestCopulaFit <- fitCopula( coredata(tsEigenProduct(optTestCRetXtsMatrix, optTestSigNoise$signal$eigenVectors)))
#simulate data to horizon
optTestSimulatedInvariantsToHorizon <- simulateDataToHorizon3( numSimulations = 52*200
, numPeriodsForward = 4 #22
, vineCopulaFit = optTestCopulaFit
, signalMarginalFit = optTestSigMarginalFits$fits
, residualMarginalFit = optTestNoiseMarginalFits$fits
, eigenVectors = optTesteig$eigenVectors #all eigenvectors
, corrIDX = corrIDX
, arimaModel = arimaModels
)
#pricing
optTestHorizonPriceVector <- as.vector(coredata(optTestPriceXtsMatrix[nrow(optTestPriceXtsMatrix),]))
optTestHorizonPrices <- horizonPrices( simulatedHorizonInvariants = optTestSimulatedInvariantsToHorizon
, horizonPriceVector = optTestHorizonPriceVector
)
#extract horizon profit-and-loss
optTestHorizonPnLs <- horizonPnLs( simulatedHorizonPrices = optTestHorizonPrices
, horizonPriceVector = optTestHorizonPriceVector
)
#compute moments
covRobResults <- robust::covRob(data = optTestHorizonPnLs)
optTestHorizonRobMean <- as.vector(covRobResults$center)
optTestHorizonRobCovPnL <- covRobResults$cov
#compute historical inverse volatility weights (for constraints)
sdWeightVec <- 1/apply(optTestCRetXtsMatrix,2,sd)/sum(1/apply(optTestCRetXtsMatrix,2,sd))
#extract 7 lowest volatility names (highest 2 will be constrained by inverse volatility weight)
constraintNames <- names(which(rank(sdWeightVec)>=7))
sdWeightVecConstraint <- sdWeightVec[constraintNames]
#compute efficient frontier
LongOnly <- TRUE
optTestOptimizedPortfolio <-
optimizeMeanVariancePortfolio( meanVector = optTestHorizonRobMean
, covarianceMatrix = optTestHorizonRobCovPnL
, horizonPriceVector = optTestHorizonPriceVector
, horizonPnLMatrix = optTestHorizonPnLs
, wealthBalance = 10000
, maxWeightConstraint = list( names = constraintNames #safe weights
, constraintWeight = sdWeightVec #all weights
, maxWeight = ifelse(LongOnly,1,100)
)
, colNames = names(optTestPriceXtsMatrix)
, longOnly = LongOnly
)
return(
list(
estimationPeriod = dateIndex
, OOSPeriod = OOSIndex
, pseudoISPeriodPlot = pseudoISPeriodPlot
, optimalResult = optTestOptimizedPortfolio$optimalResult
, minVarResult = optTestOptimizedPortfolio$minVarResult
, expectedReturn = optTestOptimizedPortfolio$expectedReturn
, standardDeviation = optTestOptimizedPortfolio$standardDeviation
, fitData = list(signalMarginals = optTestSigMarginalFits$evaluation
, noiseMarginals = optTestNoiseMarginalFits$evaluation
, copula = -999
)
)
)
}
stopCluster(cl=cl)
closeAllConnections()
gc()
cl <- NULL
loopEnd <- Sys.time()
loopEnd - loopStart
# Time difference of 1.595575 hours
# Time difference of 13.83757 mins #ON AWS 64 cores
rollingOptimizationResults <- list( portfolioNames = names(optTestPriceXtsMatrixALLweekly)
, portfolioFreq = "weeks"
, portfolioStats = rollingOptimizationResults
)
Calculating results after running one of 3 scenarios above
#Optimal Sharpe
realizedOPPortfolioMatrix<-
Return.portfolio(R = retMatrixL(optTestPriceXtsMatrixALLdaily)
, weights = createOptimalStatisticTimeSeries(optimizationResultsObject = rollingOptimizationResults
, statisticType = "opWeights"
, datePeriodType = "test"
, indexTimeSeriesFreq = "monthly")
)
colnames(realizedOPPortfolioMatrix) <- "Optimal Sharpe"
realizedOPPortfolioMatrix <- merge(realizedOPPortfolioMatrix, retVectorL(RSPd), retMatrixL(optTestPriceXtsMatrixALLdaily))
colnames(realizedOPPortfolioMatrix)[2] <- "Benchmark"
#Minimum Variance
realizedMVPortfolioMatrix<-
Return.portfolio(R = retMatrixL(optTestPriceXtsMatrixALLdaily)
, weights = createOptimalStatisticTimeSeries(optimizationResultsObject = rollingOptimizationResults
, statisticType = "mvWeights"
, datePeriodType = "test"
, indexTimeSeriesFreq = "monthly")
)
colnames(realizedMVPortfolioMatrix) <- "Minimum Variance"
realizedMVPortfolioMatrix <- merge(realizedMVPortfolioMatrix, retVectorL(RSPd), retMatrixL(optTestPriceXtsMatrixALLdaily))
colnames(realizedMVPortfolioMatrix)[2] <- "Benchmark"
References
Kramer, Nicole, and Ulf Schepsmeier. 2011. “Introduction to Vine Copulas.” Technische Universitat Munchen. https://www.statistics.ma.tum.de/fileadmin/w00bdb/www/veranstaltungen/Vines.pdf.
Markowitz, Harry. 1952. “Portfolio Selection.” Journal of Finance 7 (1). Wiley for the American Finance Association: 77–91. http://www.jstor.org/stable/2975974.
Meucci, Attilio. 2005. “Risk and Asset Allocation.” Springer Finance Textbooks. https://www.arpm.co/book/.
———. 2011. “‘The Prayer’ Ten-Step Checklist for Advanced Risk and Portfolio Management,” Feb. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1753788.
Peterson, Brian. 2014. “Developing & Backtesting Systematic Trading Strategies.” https://r-forge.r-project.org/scm/viewvc.php/*checkout*/pkg/quantstrat/sandbox/backtest_musings/strat_dev_process.pdf?root=blotter.